This is our recording and observations as we setup a kafka cluster for the first time on a EKS cluster using strimzi. In this blog we will explore in detailed way of how to setup EKS cluster and running apache kafka producer and consumer program on it.
1.Configuring the AWS CLI
Ensure that the AWS CLI is installed in your machine.If it is not installed in your machine then install it by following the link given below
After installing eksctl create a cluster using the following command
This will create a cluster by the name kafka-poc with 4 nodes.
After the cluster is created, the appropriate kubernetes configuration will be added to your kubeconfig file.
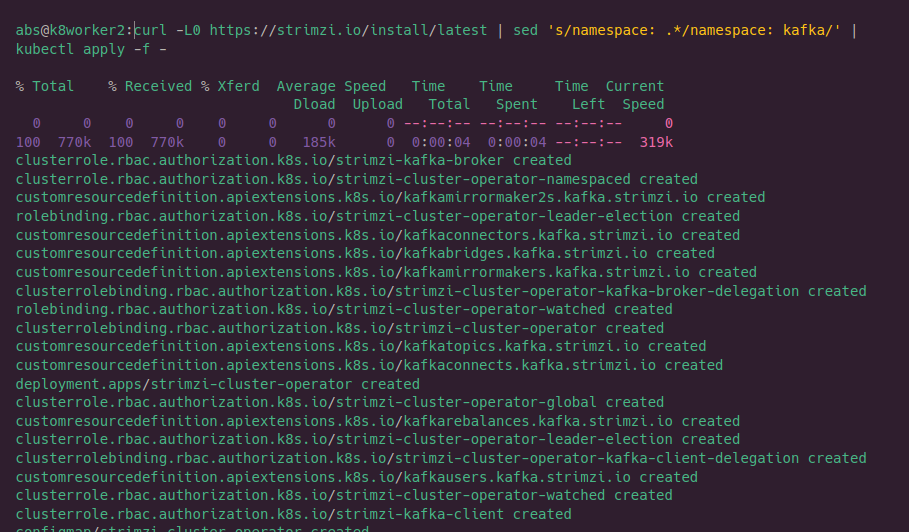
5.Install strimzi kafka operator
install strimzi operator using the following command.This command will install strimzi operator with namespace kafka.
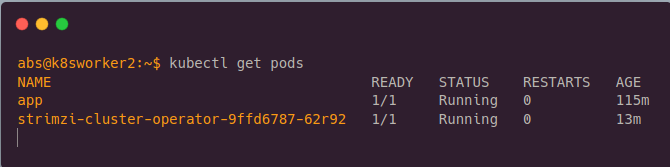
6.Checking strimzi operator is running
We have installed strimzi kafka operator in previous step. We have to check whether it is installed in your cluster using the below command. If the status is running then the strimzi operator has installed in your cluster.
6.Choosing a storage for your cluster
In kuberenetes two types of storage is there
1.ephemeral
2.persistent
If you are going to just setup kubernetes cluster for testing then you can go ahead with ephemeral storage. Suppose if you are going to setup kubernetes cluster for production then you can go ahead with persistent storage .In persistent storgae,data is stored permanantly.You have to provide a storage capacity to each node using EBS or EFS. In our setup we have used EBS for persitennt storage.
Create your amazon EBS CSI plugin IAM role with eksctl.
Here you have to replace my-cluster with your cluster name,AmazonEBSCSIDriverPolicy with your driver policy and also replace AmazonEKS_EBS_CSI_DriverRole with your driver role
This command will create iam and attach required AWS managed policy to your cluster.
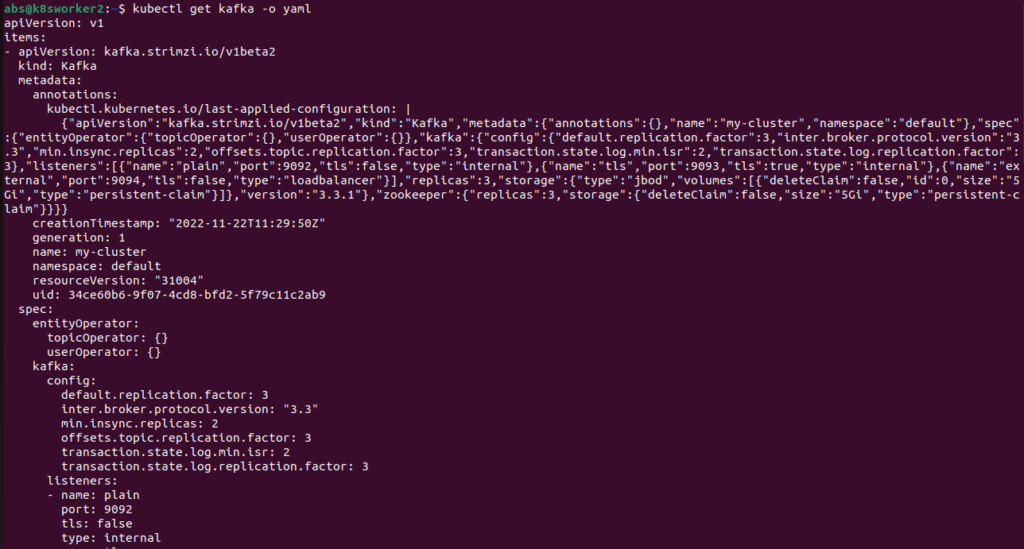
7.Install Kafka cluster operator
Run the above command and edit the yaml file as per our requirement.The example yaml file is shown below .
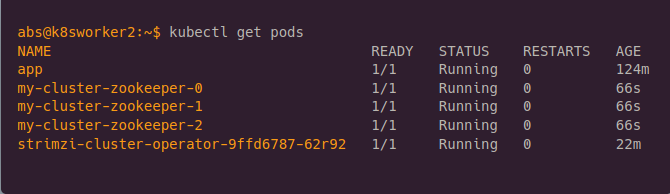
After installing kafka cluster, check zookeeper is running in your machine.
After installing zookeeper, wait till kafka has to run in the cluster.
10.Checking all the pods are running
11.Troubleshoot your problem
If any pod is in pending status check your sc(storage class),PV(persistent Volume),pvc(persistent volume claim).
Kubectl get sc,pv,pvc,svc
(i).Check SC(storage class) is in your cluster
Here two storage class is stored in your cluster such as ebs-sc, gp-2.gp-2 is the default storage class in your cluster.
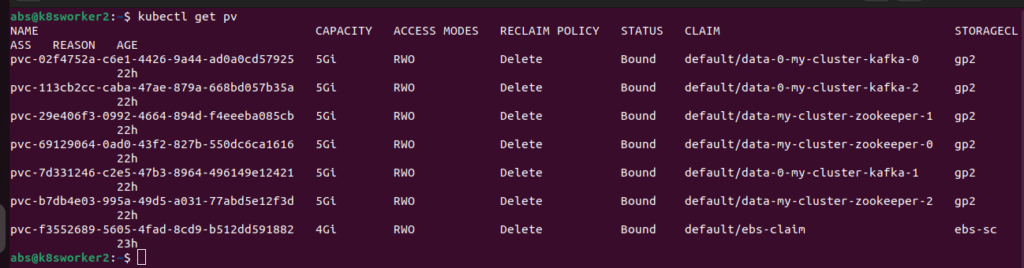
(ii).check PV(Persistent Volume) in your cluster
(iii).Check PVC(Persistent Volume Claim) in your cluster
8.To create a topic
The topic should be created for your producer and consumer program.The topic is geeting created using the following command.
9.To edit topic
10.To get the hostname and port of kafka
In this END CERTIFICATE you can see host and port under addresses field.Take that host address and port number and set it in your program as clientId.When you run producer and consumer after changing that address ,producer used to produce the message continously to topic and consumer used to consume message from topic